入門⚡Shapeless
Table of Contents

1. 入門⚡Shapeless
贅沢な名だね。 –— 湯婆婆, 『千と千尋の神隠し』
![]()
1.1. はじめに
この記事では、プログラミング言語 Scala において ジェネリックプログラミング(Generic Programming) を行うためのライブラリである shapeless の基本的な利用方法を解説します。
1.1.1. この記事で使うshapelessについて
この記事は、 shapeless 2.3.5 に基いて執筆されています。当該バージョンのshapelessは、 build.sbt において以下のようにインストールできます:
libraryDependencies += "com.chuusai" %% "shapeless" % "2.3.5"
1.1.2. この記事で使うScalaについて
この記事は、Scala 2.13.8に基いて執筆されています。Scala 3系においてもshapelessを利用することはできますが、執筆時点で筆者はScala 3に関する知識を十分に持ち合わせていませんから、Scala 3における動作に関する記述は割愛します。
1.2. ジェネリックプログラミングとは
ジェネリックプログラミングとは、ある問題領域における 構造 を表現する手段として具体的なclassやtraitを使わず、より抽象的な道具を用いて構造を表現するプログラミング手法です。
また、ジェネリックプログラミングは、JavaやScalaにおけるジェネリクス / Parametarized Typesとは関係ないため注意が必要です。
1.2.1. ジェネリックプログラミング(shapeless)が必要になる例
- 同じ型の要素を同じ順序で持つcase class同士を相互変換する
- 異なる型が混在し、なおかつ型安全な
Mapを利用する
いずれにせよ、ジェネリックプログラミングとは、クラスや型といった具体的な要素から「構造」という要素を取り出し、それ単体で物事をうまく扱おうという考え方を指しています。
ジェネリックプログラミングを使うと、構造と構成要素の型を維持しつつ、 class や trait
の垣根を飛び越えてデータを操作できるようになります。
ジェネリックプログラミングとは、オブジェクトから名前を消し去り構造に着目することだ、と言ってもよさそうです。
1.3. Shapelessに登場する基礎概念
Shapelessでは、型同士を組み合わせたり取り出したりします。この節では、この目的を達成するために用意されている道具のうち基礎的なものを紹介します。代数的データ型について知っている場合は読み飛ばしてかまいません。
1.3.1. 代数的データ型(ADTs)
先程、 1.2.1 で以下のように述べました。
ジェネリックプログラミングとは、クラスや型といった具体的な要素から「構造」という要素を取り出し、それ単体で物事をうまく扱おうという考え方を指しています。
では、 構造 とは何でしょう。数学的な難しい話は割愛しますが、 代数的データ型(Algebraic Data Types,
ADTs) を用いることで再帰を含む複雑なデータ型を表現できることがわかっています。
そして、多くの言語ではこのADTsを言語レベルである程度サポートするための機能が備えられており、
Scalaもこうした言語のうちの一つです(後述する Tuple や sealed trait などがこれをサポートしています)。
ADTsは、 直積(Product) と 直和(Coproduct、 余積とも) から成るデータ型の総称です。 数学的な詳細な説明は割愛しますが、直積は複数のデータ型をくっつけて 両方のデータを同時に表現できるようにした もの(型を組にしたもの)であり、直和は複数のデータ型をくっつけて このうちどれか一つを表現できるようにした ものです。 この2つを組み合わせることでADTsは様々な抽象的なデータ型を表現する能力を得ます。
例えば、よく知られたデータ構造である二分木は「木か葉1のいずれか」 という直和型を2つ合わせて直積にしたものと考えることができ(直和の直積)、ADTsで表現することができます。
ADTsを表現するためにScalaに最初から備わっている機能として、 タプル 、 Either 型 、 クラス 、
sealed trait などがあります。そしてshapelessは、ADTsを専門に扱い、柔軟なデータ操作を提供するためのライブラリです。
まずはScalaに備わっているADTsをサポートするための機能がどのような性質を持つか復習しましょう。
1.3.2. ScalaにおけるADTsをサポートする手段
この節では、shapelessの理解をより深めるために、Scalaで型を組み合わせるために用意されているいくつかの方法について復習します。
タプル は、複数の型を組み合わせて1つの型にします。タプル自体は最も単純な型構築子2の一つであり、それ自体多くの機能を持ちませんが、複数の型を一つにし、それをまた分解できるという最も基本的な機能を提供します。
type StringIntTuple = Tuple2[String, Int]
/* もしくは */
type StringIntTuple = (String, Int)
val tupled: StringIntTuple = ("hoge", 42)
tupled._1 // => "hoge"
tupled._2 // => 42
Either も複数の型を組み合わせて1つの型にしますが、タプルとは違い、どちらかの型であることを表現します。
実際に値を入れたり取り出したりする際には、 Left と Right とを用いてどちらの型かを教えます:
type StringIntEither = Either[String, Int]
val l: StringIntEither = Left("hoge")
val r: StringIntEither = Right(42)
クラス は、ある意味タプルの強化版です。なぜなら、複数の型を名前付きのフィールドとして持ち、さらに手続きをメソッドとして持っているからです:
case class FooClass(s: String, i: Int) {
def toString(): String = s"s: $s, i: $i"
}
sealed trait もまた、 Either の強化版です。なぜなら、 Either が提供する「型を選ぶ」という機能に付け加えて、それぞれの名前が提供されるからです。
Scalaユーザにとってお馴染の Option も sealed trait で実装されています:
sealed trait Option[+A] case class Some[+A](x: A) extends Option[A] case object None extends Option[Nothing]
ADTsの観点から見ると、 Option は Some (1要素の直積) と None (0要素の直積)との直和である、と見ることができます。
Scalaには複数の型を組み合わせて1つにするための機能がいくつも用意されている ことが分かりましたね。
それぞれの機能には以下のような共通点があることを確認してください:
- 名前を付けられるものと、付けられないものがある。
- 名前を付けられる: クラス、
sealed trait - 名前を付けられない:
Tuple、Either
- 名前を付けられる: クラス、
- 3つ以上の型を組み合わせられるものと、組み合わせられないものがある。
- 組み合わせられる:
Tuple(ただし、Tuple22までしか用意されていないので22個が上限)、クラス、sealed trait - 組み合わせられない:
Either
- 組み合わせられる:
1.3.3. Shapeless
前項では、Scalaの言語機能でもある程度ADTsを実装できることを示しました。しかしながら、Scalaの標準言語機能のみを使ってADTsを実装する場合、以下のような制約が伴います:
Tupleが22要素までにしか対応しておらず、これを超えるような直積をともなうADTsを表現できない。TupleNとTupleN-1,TupleN+1との間に型的な関連がほぼ無いため、相互運用性が低い。- クラスや
sealed traitを用いたADTsは、型が具体的すぎるため柔軟性が低い。- 例えば、同じ構造を持つクラス同士を変換したくても、 手で全ての要素を取り出してコンストラクタに渡さなければならない
Eitherは2要素にしか対応しておらず、2要素を越えるADTsを表現するためには複数のEitherを組み合わせる必要があるが、その運用は複雑を極める。
ShapelessはこのようなADTsを扱う上での問題をできるだけ解消し、 ユーザがADTsの操作に注力できるようにします。Shapelessは従前の問題を解消しています:
- 事実上無制限長の直積・直和を表現できる。
- 直積はその長さによって型同士の関連性を持つことができる。
- 同じ構造のADTsは同じ表現になる。
case classとの相互運用を行う方法が用意されている。
ここからは、実際にshapelessを使う方法について解説していきます。
1.4. HList
Shapelessで直積を表現するには、 HList データ型を使います。 HList は、
前項で登場したタプルと似た振舞いをします。つまり、複数の型を1つにし、
その値がすべての型の値を持つことを保証します。 HList は、 Heterogeneous List (異種混交リスト)の略です。
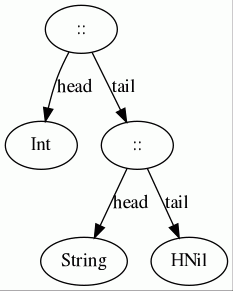
HList を構築するには、 :: を型の間に置き、最後に HNil を置きます。
:: は、型構築子としても、値構築子としても使うことができます。
import shapeless.{::, HNil}
type IntStringHList = Int :: String :: HNil // (Int, String) にほぼ対応する
val hlis: IntStringHList = 42 :: "foo" :: HNil
// hlis: shapeless.::[Int, shapeless.::[String, HNil]] = 42 :: "foo" :: HNil
:: と HNil は HList のサブタイプです。
val hlis: HList = 10 :: "bar" :: HNil val hn: HList = HNil
形が分かっている HList からは型安全に値を取り出すことができます:
def stringifyIntString(is: IntStringHList): String = {
val i = is.head // type safe -- 常にInt
val s = is.tail.head // type safe -- 常にString
...
}
match 式で内容を取り出すこともできます:
hlis match {
case (i: Int) :: (s: String) :: HNil => s"int: $i, string: $s"
} // => "int: 42, string: foo"
1.4.1. 型の中置記法
冒頭で示したコードのうち、返り値の型に注目してください。
val hlis: IntStringHList = 42 :: "foo" :: HNil // hlis: shapeless.::[Int, shapeless.::[String, HNil]] = 42 :: "foo" :: HNil
shapeless.::[Int, shapeless.::[String, HNil]] がリストのような形式になっているのが分かるはずです。
Scalaには2-arityの型を中置する記法がある3ため、これを Int :: String :: HNil と書けるのです。
1.4.2. case class との違い
先程の hlis とほぼ同じ内容のものを case class で作成して比較してみます。
case class Hlis(first: Int, second: String) val hlis2 = Hlis(42, "foo")
case class で作った hlis2 は、 Hlis という固有のクラス名と、 first, second
という固有のフィールド名を持っています。その一方、 hlis は Int と String をこの順で保持している HList であること以外に何も情報を持ちません。いくつかの性質を表にまとめました:
| 性質 | case class | HList | Tuple |
|---|---|---|---|
| いくつでもフィールドを持てる | true | true | false |
| 型がフィールド名を持つ | true | false | false |
| 型が固有名を持つ | true | false | false |
HList は、 case class ほど強い表現力を持たない代わりに、動的にフィールドを追加したり、特定のフィールドを持つすべての
HList を受け取るメソッドを定義したりといった強い柔軟性を持つことができています。
1.4.3. 例: 色を混ぜる
HList を利用した簡単な例として、赤・緑・青・透明度の4要素で表現される色を混ぜ合わせるメソッドを定義してみましょう。
type RGBA = Int :: Int :: Int :: Int :: HNil
val red: RGBA = 255 :: 0 :: 0 :: 255 :: HNil
val green: RGBA = 0 :: 255 :: 0 :: 255 :: HNil
def brendAverage(xs: Int :: HList, ys: Int :: HList): Int :: HList = (xs, ys) match {
case (x :: (x2: Int) :: HNil, y :: (y2: Int) :: HNil) => (x + y) / 2 :: (x2 + y2) / 2 :: HNil
case (x :: (x2: Int) :: xs, y :: (y2: Int) :: ys) => (x + y) / 2 :: brendAverage(x2 :: xs, y2 :: ys)
case otherwise => ???
}
brendAverage(red, green) // => 127 :: 127 :: 0 :: 255 :: HNil
直接 HList をインデックスアクセスすることもできましたが、今回は HList
らしく再帰的に定義してみました。この brendAverage メソッドは、
赤・緑・青の3要素しか持たない色を渡しても動作します:
brendAverage(255 :: 0 :: 255 :: HNil, 0 :: 255 :: 0 :: HNil) // => 127 :: 127 :: 127 :: HNil
既にshapelessがもたらす柔軟性が現われ始めていますね。
1.4.4. HListから特定のフィールドを抽出する(shapeless.ops.hlist)
shapeless.ops.hlist.Selector を使うと、 HList から特定のフィールドを抜き出すことができます。この機能は、メソッドからは具体的な HList の形が分からないが特定の型を含んでいることを要求したい場合に便利です。
メソッドの implicit 引数として Selector を要求することで、特定のフィールドを抜き出せるようになります。該当する Selector はコンパイル時に自動的に渡されます。
def getInt[H <: HList](h: H)(implicit sel: shapeless.ops.hlist.Selector[H, Int]) = {
// この中からは、Hの具体的な型がわからないことに注目。
// 型がわからなくても、SelectorがあることによってInt型が含まれていることが保証される
s"$h has int member ${sel(h)}"
}
getInt("foo" :: 42 :: HNil) // => "foo :: 42 :: HNil has int member 42"
getInt("foo" :: false :: HNil) // => コンパイラはSelectorを発見できないのでコンパイルエラーになる
この例ではフィールドの抽出でしたが、 一般に具体的な形が分からない HList を操作するようなメソッドを定義するときは、 implicit で ops を受け取り、呼び出せるかどうかをコンパイラに委ねるというパターンになります。
shapeless.ops.hlist には、他にも以下のような ops が用意されています:
Align:HListを指定した順序に並び換えるGeneric(後述)と組み合わせるときなどの型合わせに使う
Diff:HListから特定の型集合を削除する- 余分な型を捨てたいときに使う
Prepend:HListに別のHListを追加する- なにか
HListを付け加えて返したいときなどに便利
- なにか
1.5. Coproduct
Shapelessで直和を表現するには、 Coproduct データ型を使います。 Coproduct は、前項で登場した Either と似た振舞いをします。つまり、複数の型を1つにし、その値がどちらかの型の値を持つことを保証します。
Coproduct を構築するには、 :+: を型の間に置き、最後に CNil を置きます。
import shapeless.{:+:, CNil}
type IntOrString = Int :+: String :+: CNil // Either[Int, String]にほぼ対応する
Coproduct は Either と異なり、リスト状の構造になっています:
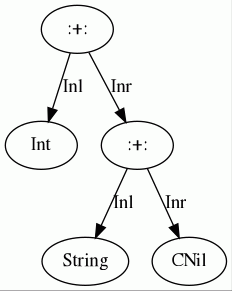
このため、 Coproduct は3つ以上の型を自然に組み合わせることができます。 HList に似ていますね。
1.5.1. Inl / Inr
Coproduct の値構築子は Inl と Inr です4。これは Either における Left と Right に対応します。
import shapeless.{Inl, Inr}
val i: IntOrString = Inl(42) // Left(42) に対応する
val s: IntOrString = Inr(Inl("foo")) // Right("foo")に対応する
Inl と Inr の唯一の役割は、元々のプリミティブな値を Coproduct の型の文脈に押し上げることです。言い換えると、型レベルの標識を行い、単なる Int なのか、それとも Int :+: String :+: CNil 上の Int なのかを区別させるためだけに存在しています。
さっきのは MT免許 です。 AT免許 として Inject が用意されています。 Inl や Inr を省略できます:
import shapeless.syntax.inject._
val s2: IntOrString = "foo".inject[IntOrString] // => Inr(Inl("foo"))
// これは以下の表現と等価
import shapeless.ops.coproduct.Inject
val s3: IntOrString = Inject[IntOrString, String].apply("foo")
先程も述べた通り、 Coproduct が Either よりも優れている点として、 3つ以上の型を自然に組み合わせられる というものがあります。
case class ErrorA(msg: String)
case class ErrorB(msg: String)
case class ErrorC(msg: String)
case class ErrorD(msg: String)
type Errors = ErrorA :+: ErrorB :+: ErrorC :+: ErrorD :+: CNil
val ec: Errors = ErrorC("injecting").inject[Errors] // => Inr(Inr(Inl(ErrorC(...))))
Either でも似たような事はできますが、結合順序の定義が悪いため Coproduct ほど洗練された定義を与えられません。
1.5.2. Inl / Inr 補足
これは補足なのでスキップしてかまいません。
Coproduct が右向きのリスト状に構成されている都合上、 Inl は常に値を保持する役回りであり、 Inl は型を1つずらす操作に対応します。このため、 Coproduct の値表現は常に Inr(...(Inl(値))) という表現になります。この感覚には少し慣れが必要です。というのも、 HList の場合は順番が重要であることは直感的に理解できる一方で、 Coproduct で順番を気にしなければならないことは直感的ではないからです(実際、 sealed trait では順番を気にする必要がありません)。
HList の値を構築したときは複数の束ねたい型と唯一の値構築子 :: を用いましたが、 Coproduct の場合は渡す型は一つだけであり、 Coproduct のどの型にあてはまるかを指示するために Inl と Inr という型構築子を使い分けます5。
リボルバー銃の弾倉を回す操作と、引き金を引く操作になぞらえると分かりやすいかもしれません。必要な数だけ弾倉を回し、引き金を引くことで望みの型が飛び出すのです。
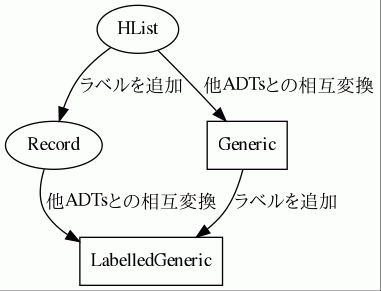
1.6. Record
前項では、 HList を構築する方法と Coproduct を構築する方法について学びました。ここでは HList にフィールド名の概念を追加した Record について学びます。
Recordはちょうど型安全でポリモーフィックな Map のように振舞い、フィールド名を用いて型安全に値を取り出すことができます。Rubyといった言語の連想配列が、さらに型安全になった様子をイメージすると分かりやすいと思います。
Recordはちょうど HList 以上 case class 未満の表現力を持ちます。
前掲の表にRecordを増やしてみることでこれを確認してみましょう:
| 性質 | case class | Record | HList | Tuple |
|---|---|---|---|---|
| いくつでもフィールドを持てる | true | true | true | false |
| 型がフィールド名を持つ | true | true | false | false |
| 型が固有名を持つ | true | false | false | false |
Recordはそれ自体に名前を持ちませんが、各フィールドには名前を持つことができ、 その名前でフィールドにアクセスできます。
1.6.1. ->> を使ってRecordを構築する
HList を構築する方法と ->> とを組み合わせることで、Record を構築することができます。
import shapeless.syntax.singleton._ // ->>のために必要
val rec1 = ("foo" ->> "bar") :: ("hoge" ->> 42) :: HNil // フィールド"foo"と"bar"を持つRecordを作成
Recordの型は、 FieldType[K, V]
6を集めた HList になります。
上の例では、 rec1 の型は FieldType["foo", String] :: FieldType["hoge", Int] :: HNil です。
Record には apply が定義されているので、よくある Map と同じようにアクセスできます:
rec1("foo") // => "bar"
+ や - といったメソッドが用意されており、フィールドを自由に追加・削除できます:
rec1 + ("buzz" ->> true) // => ("foo" ->> "bar") :: ("hoge" ->> 42) :: ("buzz" ->> true) :: HNil
rec1 - "foo" // => ("hoge" ->> 42) :: HNil
1.6.2. Record構文を使ってRecordを構築する
shapeless.record に、 Record を構築するための構文が定義されています。
import shapeless.record._ val rec2 = Record(foo = 42, bar = "hoge")
ただしこの構文は Symbol に依存しているため、キーの型は String ではなく Symbol になります。
rec2(Symbol("foo")) // => 42
1.6.3. Recordの型構築構文
->> を駆使する代わりに、 Record.`キー -> 型, ...`.T と書くことで、 Record 型を構築することができます。
type Rec1 = Record.`"foo" -> String, "hoge" -> Int`.T
1.6.4. Recordから特定のフィールドを抽出する(shapeless.ops.record)
1.4.4で説明したのと同様に、 Record に対する操作を定めた shapeless.ops.record を使うことで Record 全体の型が分からなくてもフィールドの追加や削除などを行うことができます。
メソッドの implicit 引数として Extractor を要求することで、特定のフィールドを抜き出せるようになります。該当する Extractor はコンパイル時に自動的に渡されます。
import shapeless.ops.record.Extractor
def getAge[H <: HList](rec: H)(
implicit ex: Extractor[H, Record.`'age -> Int, 'name -> String`.T]
) = {
val extracted = ex(rec)
val name = extracted(Symbol("name"))
val age = extracted(Symbol("age"))
s"$name is $age year(s) old"
}
val me = Record(name = "Windymelt", age = 29, gender = "male")
val usa = Record(name = "USA", capital = "Washington D.C.", age = 246)
getAge(me) // => "Windymelt is 29 year(s) old"
getAge(usa) // "USA is 246 year(s) old"
面白いことに、 me と usa の型はそれぞれバラバラですが、 getAge はこの違いを乗り越えて name フィールドと age フィールドのみを取り出し、名前と年齢を表示できていますね。
1.7. 任意のADTsに対して操作を定義する
この節では、任意のADTsと HList ・ Coproduct とを相互変換する Generic と、それの Record 版である LabelledGeneric について解説します。
今まで説明した内容では、現実の case class と HList との相互作用については扱ってきませんでした。これから説明する Generic / LabelledGeneric はこの二者のインターフェイスとして作用し、ビジネスロジックを記述する一般のScalaの世界と、抽象化の力を得たshapelessの世界とを行き来できるようにします。
1.7.1. Generic
shapeless.Generic を使うことで、 case class や Tuple と HList とを相互変換できます:
case class Person(name: String, age: Int, gender: String)
val me1 = Person("Windymelt", 29, "male")
shapeless.Generic[Person].to(me1) // => "Windymelt" :: 29 :: "male" :: HNil
shapeless.Generic[Person].from("Windymelt" :: 29 :: "male" :: HNil) // => Person("Windymelt", 29, "male")
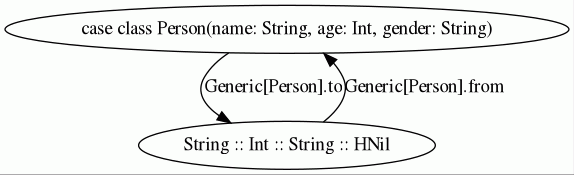
to と from がどちらの向きかを覚えるには少し慣れが必要です。
- 例: 任意のcase classからIdを取り出す
Idという型をフィールドとして持っている任意のcase classからIdを取り出してみましょう。必要な道具は、GenericとSelectorです。case class Id(x: Long) case class Car(id: Id, mass: Int, cost: Int) case class Tweet(id: Id, user: String, content: String) def selectId[A, H <: HList](x: A)( implicit gen: shapeless.Generic.Aux[A, H], sel: shapeless.ops.hlist.Selector[H, Id] ): Id = { val hlist = gen.to(x) sel(hlist) } selectId(Car(Id(123), 1000, 3000000)) // => Id(123) selectId(Tweet(Id(666), "@windymelt", "#welovescala")) // => Id(666)互いに全く関係の無い
CarとTweetからIdを取り出せました。shapelessの強力さがお分かりいただけましたか?shapeless.Generic.Auxという型が使われていることに注目してください。以下の理由から、Genericの代わりにGeneric.Auxを使う必要があります:Selectorは取り出したい型を含んだHListを型引数として要求するGenericは変換を担当するが、その変換結果どのようなHListになるかは直接は得られないGeneric.Auxは変換結果を型引数として露出させてくれるので、Generic.Aux[A, H]とSelector[H, Id]というふうに書ける- これにより、二者の関係が明確になり、正常に連携できるようになる
- 「
AをHに変換し、HからIdを取り出す」と読めるようになる
Generic.Auxを使わない場合、変換結果の型が分からないのでSelectorに手でHListの型を教えてやることになってしまい、せっかく得た柔軟性が壊れてしまいます。opsと連携させるときはGeneric.Auxを使う、と覚えておくとよいでしょう。
1.7.2. LabelledGeneric
HList を変換する Generic があるように、 Record に対応する LabelledGeneric も存在します。
使い方はGenericとほぼ同じです:
shapeless.LabelledGeneric[Person].to(me1)
// => ('name->> "Windymelt") :: ('age ->> 29) :: ('gender ->> "male") :: HNil
- 例: 任意のcase classからnameフィールドを取り出す
1.7.1.1でやったように、今回は
LabelledGenericを使ってcase classから特定の名前を持つフィールドを取り出してみましょう。case class Person(name: String, age: Int, gender: String) val zundamon = Person("Zundamon", 1, "???") case class Cat(name: String, age: Int) val tama = Cat("Tama", 3) def greeting[A, H <: HList](x: A)( implicit gen: shapeless.LabelledGeneric.Aux[A, H], ext: shapeless.ops.record.Extractor[H, Record.`'name -> String`.T] ): String = { val extracted = ext(gen.to(x)) val name = extracted(Symbol("name")) s"Hi, $name !" } greeting(zundamon) // => "Hi, Zundamon !" greeting(tama) // => "Hi,Tama !"クラスの構造を乗り越えて、
nameというフィールドがありさえすれば何でも受け付けられるメソッドgreetingを定義することができました。 非常に強力だとは思いませんか? @implicitNotFoundの活用
また、Scala標準の
@implicitNotFoundアノテーションを使うことで、ユーザーフレンドリーなDXを提供できます:import scala.annotation.implicitNotFound def greeting[A, H <: HList](x: A)( implicit @implicitNotFound("HListに変換できません") gen: shapeless.LabelledGeneric.Aux[A, H], @implicitNotFound("name: Stringを持つオブジェクトである必要があります") ext: shapeless.ops.record.Extractor[H, Record.`'name -> String`.T] ): String = { val extracted = ext(gen.to(x)) val name = extracted(Symbol("name")) s"Hi, $name !" } greeting(42) // コンパイルエラー: HListに変換できません他にも、
LabelledGenericを使った色々なアイデアが思い浮かびます:- 任意の
case classをJSONに変換する - 同じ名前のフィールドを持つ
case class同士を変換し、足りないフィールドをデフォルト値で補う
これは読者への宿題とします。
- 任意の
1.8. Poly
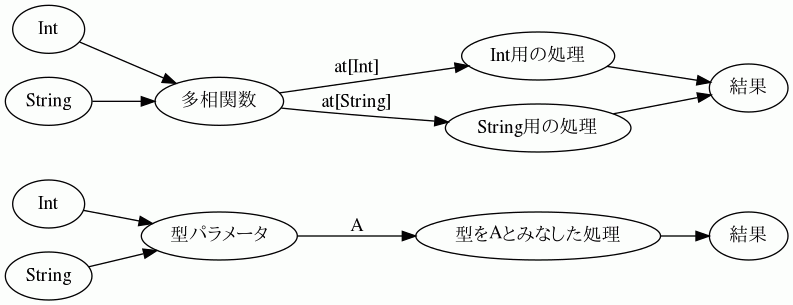
ここでは、関数をポリモーフィックに拡張した、つまり引数として様々な型を取ることをサポートした関数(多相関数)である Poly の使い方について説明します。
一般的な関数は特定の型を引数に取りますが、多相関数は複数の引数型に対して処理を定義できます。
1.8.1. 型パラメータとの違い
型パラメータ(ジェネリクス)では型を全称量化する、つまり「なんでもよい型」について扱っており、具体的な型のことを知りませんでした。多相関数は、引数としてやってくる型について知っており、なおかつそれが複数であるような関数です。
- 共通点: 異なる型を受け取る
- 型パラメータ: 型を抽象化して変数的に扱う
- 多相関数: 具体的な型はそのまま、型に応じた異なる処理を行う
1.8.2. PolyをHListに適用する
これまでは HList を直積、つまりADTsを構成するための道具として解説してきましたが、 head や tail といった操作をサポートしていることからも分かるとおり、 HList は通常の List のようにも振舞います。
HList を List とみなすと、以下のような疑問が浮かびます:
Listに対して定義されているfoldLeftやmapなどの高階操作をHListにも適用できるか?
HList は一種の List なので、各要素に関数を適用すれば foldLeft や map を実装できそうです。しかし以下のような問題にぶつかります。
- 本質的に
HListは複数の型をくっつけたものなので、高階関数に与える関数の型を決定できない - 関数の引数を
Anyにすれば解決するが、型安全性が損なわれてしまう
コード例でこのことを確認してみましょう:
def processHList[H <: HList](hs: H) = {
val f = ??? // fの引数の型をどう定義したらよい?
hs.map(f)
}
2. Ops 紹介
ここでは、shapelessが提供している各種の ops を紹介します。 ops を使うことで、 HList や
Coproduct を型レベルで操作し、より柔軟な処理を表現できるようになります。
2.1. Adjoin – 結合する
shapeless.ops.Adjoin は、複数の HList または Coproduct を結合してくれます。
import shapeless._
import ops.adjoin._
def join[H <: HList, I <: HList, O](h: H, i: I)(implicit adjoin: Adjoin.Aux[H :: I :: HNil, O]): O = {
adjoin(h :: i :: HNil)
}
val h = 10 :: "foo" :: true :: HNil
val i = 20 :: "bar" :: false :: HNil
val hi: Int :: String :: Boolean :: Int :: String :: Boolean :: HNil = join(h, i)
// => 10 :: "foo" :: true :: 20 :: "bar" :: false :: HNil
型が不明な2つの HList または Coproduct を結合する場合に便利です。
Adjoin を用いたルータの実装がShapelessのリポジトリに存在します。
2.2. coproduct.*
ここでは、 shapeless.ops.coproduct オブジェクト以下に定義されているOpsを紹介します。
2.2.1. coproduct.Inject – 型を Coproduct 上に持ち上げる
shapeless.ops.coproduct.Inject は、単純な型 I を Coproduct 上の型 C に写します。例えば、
単純な型 String の値 "foo" を Int :+: String :+: Boolean :+: CNil 上の Inr(Inl("foo")) に写します。
import shapeless._
import ops.coproduct.Inject
def inject[C <: Coproduct, I](i: I)(implicit inj: Inject[C, I]): C = {
inj(i)
}
type ISB = Int :+: String :+: Boolean :+: CNil
val isb1: ISB = inject[ISB, String]("foo")
// isb1: ISB = Inr(tail = Inl(head = "foo"))
val isb2: ISB = inject[ISB, Boolean](false)
// isb2: ISB = Inr(tail = Inr(tail = Inl(head = false)))
ここでは inject[ISB, String] などと型を明示していますが、
省略するとうまく型推論が働かないようなので、省略できません。
2.2.2. coproduct.Selector – Coproduct から型を取り出す
shapeless.ops.coproduct.Selector は、 Coproduct 型から特定の型を Option に包んで取り出します。
Coproduct にその型が含まれていなかった場合は、 None を返します。
import shapeless._
import ops.coproduct.Selector
def select[I, C <: Coproduct](c: C)(implicit sel: Selector[C, I]): Option[I] = {
sel(c)
}
type ISB = Int :+: String :+: Boolean :+: CNil
val isb1: ISB = Inl(42)
// isb1: ISB = Inl(head = 42)
val isb2: ISB = Inr(Inr(Inl(false)))
// isb2: ISB = Inr(tail = Inr(tail = Inl(head = false)))
val i: Option[Int] = select[Int, ISB](isb1)
// i: Option[Int] = Some(value = 42)
val b: Option[Boolean] = select[Boolean, ISB](isb2)
// b: Option[Boolean] = Some(value = false)
Select は、おおむね Inject と逆向きの働きをします。
2.2.3. coproduct.At – Coproduct にインデックスアクセスする
shapeless.ops.coproduct.At は、 Coproduct 型の特定位置の型にアクセスします。例えば、ある
Coproduct 型 C の値について、その2番目の型にアクセスするといった事が可能です。
実際にその値が2番目の型であるようなときは Some を返し、そうではなかった場合は None を返します。
import shapeless._
import ops.coproduct.At
type ISB = Int :+: String :+: Boolean :+: CNil
val isb1: ISB = Inl(42) // Coproductのうち0番目の型を使っている
// isb1: ISB = Inl(head = 42)
val isb2: ISB = Inr(Inl("foo")) // Coproductのうち1番目の型を使っている
// isb2: ISB = Inr(tail = Inl(head = "foo"))
// 型レベルで表現された自然数。
// shapelessは型レベルでHList / Coproductを扱うため、インデックスアクセスなどの自然数が必要になる局面では自然数を型レベルに持ち上げる必要がある
val zero = nat._0
// zero: _0 = shapeless._0@3c7fcf26
val one = nat(1)
// one: Succ[_0] = Succ()
val two = nat(2)
// two: Succ[Succ[_0]] = Succ()
def at[C <: Coproduct, N <: Nat, O](c: C, idx: N)(implicit atInstance: At.Aux[C, N, O]): Option[O] = {
atInstance(c)
}
at(isb1, zero) // zeroを与えたときにのみvalueが得られる
// res0: Option[Int] = Some(value = 42)
at(isb1, one)
// res1: Option[At.<refinement>.this.type.A] = None
at(isb1, two)
// res2: Option[At.<refinement>.this.type.A] = None
at(isb2, zero)
// res3: Option[Int] = None
at(isb2, one) // oneを与えたときにのみvalueが得られる
// res4: Option[At.<refinement>.this.type.A] = Some(value = "foo")
at(isb2, two)
// res5: Option[At.<refinement>.this.type.A] = None
coproduct.Select が実際の型を使って値を取り出していたのとは対照的に、 coproduct.At
では直接インデックスを与えてアクセスします。
2.2.4. coproduct.IndexOf – 型レベルインデックスを得る
coproduct.At では Coproduct 型からインデックスを使って要素型を得ていましたが、
coproduct.IndexOf はちょうど逆の操作を行います。つまり、 Coproduct 型とその要素型を使って、
要素型が Coproduct 型のどの位置にあるのかを得るのです。
例えば、 Int :+: String :+: Boolean :+: CNil であるような型 ISB があるとき、 IndexOf
を使うことで String が ISB のどの位置にあるのかを型レベルで得ることができます。
import shapeless._
import ops.coproduct.IndexOf
// IndexOfはshapeless 2.4.0 以降でしか使えないことに注意
type ISB = Int :+: String :+: Boolean :+: CNil
def getIdx0[C <: Coproduct, A](implicit idx: IndexOf[C, A]): Nat = {
idx()
}
// 型レベルの自然数なので、Nat型につぶすと内容が見えなくなる
val n1: Nat = getIdx0[ISB, Int]
// n1: Nat = shapeless._0@1d12be22
val n2: Nat = getIdx0[ISB, String]
// n2: Nat = Succ()
val n3: Nat = getIdx0[ISB, Boolean]
// n3: Nat = Succ()
// 型パラメータを使ってNatを自由にする
// よくあるミスなので入出力の型を自由にしておくことを忘れないようにする
def getIdx[C <: Coproduct, A](implicit idx: IndexOf[C, A]): idx.Out = {
idx()
}
val m1 = getIdx[ISB, Int]
// m1: _0 = shapeless._0@1d12be22
val m2 = getIdx[ISB, String]
// m2: Succ[_0] = Succ()
val m3 = getIdx[ISB, Boolean]
// m3: Succ[Succ[_0]] = Succ()
def check[N <: Nat](n: N, m: Int)(implicit ev: ops.nat.ToInt[N]): Boolean = {
ev() == m
}
check(m1, 0)
// res0: Boolean = true
check(m2, 1)
// res1: Boolean = true
check(m3, 2)
// res2: Boolean = true
- Opsを使う上での注意点
Opsを使う際は、入出力する型に注意が必要です。 この例にもあるように、出力型を
Natと書いてしまうと、以下のような事が起こり、正しく結果を導けなくなります。- 前提として、後続の処理で型情報を利用するためには、 なるだけ具体的(narrow)な型をコンパイラが知っている必要がある
- 返り値の型を
Natにすると、型が具体的なNatに固定され、出力された値は単なるNatとして扱われる(wideningが発生する)ため、具体的な型情報が消失する(どのNatなのかは消失する) - 具体的な型情報が不明になるので、後続の処理では型レベルの数値が分からなくなる
これを防ぐためには、以下のことを心掛けてください:
- 引数や返り値の型として、直接
HListやCoproduct、Natを指定しない。 - 引数や返り値の型はパラメータ化し、
H <: HList、C <: Coproduct、N <: Natのように型境界を用いた表現にするか、Nat.OutのようなOut型を活用する- こうすることで型が自由になり、コンパイラがより具体的な型を推論できるようになる
2.2.5. wip
2.3. hlist.*
2.3.1. wip
2.4. record.*
2.4.1. record.Selector – キーをもとに Record からフィールドを取り出す
shapeless.ops.record.Selector は、キーを使って Record からフィールドを取り出します。
import shapeless._
import syntax.singleton._ // for ->>
import record._ // for .get
val r = ("foo" ->> 42) :: ("bar" ->> 666) :: ("buzz" ->> 100) :: HNil
// r: Int with labelled.KeyTag["foo", Int] :: Int with labelled.KeyTag["bar", Int] :: Int with labelled.KeyTag["buzz", Int] :: HNil = 42 :: 666 :: 100 :: HNil
// getメソッドがSelectorを要求する
r.get("foo")
// res0: Int = 42
Selector はよく使われるため、 shapeless.record を import して使えるようになる .get
メソッドとして使うことができます。
メソッド内で使う場合などは implicit を使って Selector を要求します:
import shapeless.ops.record.Selector
def getFooBar[R <: HList](r: R)(
implicit sf: Selector[R, "foo"],
sb: Selector[R, "bar"],
): String = {
val foo = r.get("foo")
val bar = r.get("bar")
s"$foo, $bar"
}
getFooBar(r) // : String = "42, 666"
2.4.2. record.SelectAll – 同時に複数のフィールドを取得する
shapeless.ops.record.SelectAll は、前項で説明した Selector と似ていますが、
同時に複数のフィールドを取得します。
import shapeless._
import syntax.singleton._ // for ->>
import ops.record.SelectAll
val r = ("foo" ->> 42) :: ("bar" ->> 666) :: ("buzz" ->> 100) :: HNil
// r: Int with labelled.KeyTag["foo", Int] :: Int with labelled.KeyTag["bar", Int] :: Int with labelled.KeyTag["buzz", Int] :: HNil = 42 :: 666 :: 100 :: HNil
def getFooBar[R <: HList](r: R)(
implicit saf: SelectAll[R, "foo" :: "bar" :: HNil]
): String = {
// pattern matchできて便利
val f :: b :: HNil = saf(r)
s"$f, $b"
}
getFooBar(r)
// res0: String = "42, 666"
Selector がキーの型を受け取っていたのと異なり、 SelectAll はキーの HList
を受け取っていることに注目してください。そして、 SelectAll.apply は HList を返すため、
これをこのまま分割代入できます。
3. Further Reading
- https://github.com/milessabin/shapeless/blob/main/core/shared/src/main/scala/shapeless/lenses.scala には、Monocleにも登場する
Lensとの組み合わせが実装されています。 - https://github.com/milessabin/shapeless/blob/main/core/shared/src/main/scala/shapeless/poly.scala には、多態な関数
Polyの実装と、そのHListとの組み合わせが実装されています。 - JSONライブラリ
Circeが提供するcirce.shapesモジュールは、JSONとHListとの相互変換をサポートします。
4. 参考文献
4.1. The Type Astronaut's Guide to Shapeless
underscoreioによる The Type Astronaut's Guide to Shapeless (英語) はshapelessの仕組みを順に解説してくれる良著です。shapelessの各構成要素について知りたい場合は必ず読むと良いでしょう。
Footnotes:
木構造において、 それ以上木構造が深くならないような部分のことを葉と呼びます。
値を持ちうる通常の意味での型ではなく、型を代入することで型を生成する、関数のような型のことを型構築子(型コンストラクタ)と呼びます。
Inは Injection の略で、圏論の用語に由来しています。型A, Bのそれぞれから余積A+Bに写すような射のことをCanonical injection(標準入射)と呼びます。 https://ja.wikipedia.org/wiki/%E4%BD%99%E7%A9%8D 。個人的には非常に難解な名付けで、良くないと思っています。
この面白い対称関係は、直積と余積が圏論的双対になっていることに由来するものだと思いますが、専門家ではないのでわかりません。